- 写在最前
- HashMap为什么线程不安全
- HashTable为什么是线程安全的
- synchronized方法的作用
- TreeMap的实现原理
- HashSet是怎么去重的
- HashMap和HashTable的区别
- HashSet和HashMap的区别
- HashMap扩容原理
- 快速失败和安全失败
- HashMap和HashTable如何进行HashCode的计算
- 为什么String, Integer这样的wrapper类适合作为键?
- JDK8中的HashMap
- 参考文档
写在最前
最近复习了一下Java的面试题,做了些笔记,将他发在博客上,做持久化处理。
HashMap为什么线程不安全
在JDK7中,HashMap底层是一个Entity数组,当发生Hash冲突的时候,HashMap采用的是链表的方式来解决。 在对应的数组位置存放链表的头节点,对链表而言,新加入的节点从上一个节点接下去,在多线程环境中,后面的操作会覆盖之前的写入操作。
在JDK8中,HashMap是通过数组链表+红黑树的形式存在的,相对JDK7做出了很多优化。
HashTable为什么是线程安全的
HashTable在put和get操作的时候,都加入了 synchronized 进行同步。
synchronized方法的作用
synchronized 关键字,代表这个方法加锁,相当于不管哪一个线程(例如线程A),运行到这个方法时,都要检查有没有其它线程B(或者C、 D等)正在用这个方法(或者该类的其他同步方法),有的话要等正在使用synchronized方法的线程B(或者C 、D)运行完这个方法后再运行此线程A,没有的话,锁定调用者,然后直接运行。
synchronized有4中操作方式:
-
修饰一个代码块
对某一代码块使用,synchronized后跟括号,括号里是变量,这样,一次只有一个线程进入该代码块.此时,线程获得的是成员锁。
public void main(){ system.out.print("start"); synchronized(this){ system.out.print("loading"); } system.out.print("end"); } -
修饰一个方法
被修饰的方法被称为同步方法,作用范围是整个方法,作为对象是调用这个方法的对象。
public synchronized void test(){ for(int i = 0,i<10;i++){ system.out.print(Thread.currentThread.getName()+"loading"); } } 如果用多线程方式调用这个方法,我们会看到,每个线程调用都是独立的,即一个线程循环完了之后,释放了锁,下一个线程才会获取锁进行调用。 -
修饰一个静态方法
由于一个class不论被实例化多少次,其中的静态方法和静态变量在内存中都只有一份。 所以,一旦一个静态的方法被声明为synchronized。此类所有的实例对象在调用此方法,共用同一把锁,我们称之为类锁。
-
修饰一个类
当修饰一个类的时候,作用和修饰静态方法类似,作用对象都是调用这个类的所有对象。
synchronized总结:
-
对象锁是用来控制实例方法之间的同步,而类锁是用来控制静态方法(或者静态变量互斥体)之间的同步的。 类锁只是一个概念上的东西,并不是真实存在的,他只是用来帮助我们理解锁定实例方法和静态方法的区别的。
-
无论synchronized 关键字加在方法上面还是对象上面,他的作用都是非静态的,它取得的锁的对象。 如果synchronized作用是在静态方法或者类上,则他的取得的锁是类,该类下的所有对象共用同一把锁。
-
每个对象都只有一把锁,谁拿到锁谁就可以运行这段代码。
-
实现同步时需要很大的系统开销的,特殊情况下还可能造成死锁。
TreeMap的实现原理
TreeMap继承于AbstractMap,实现了Cloneable接口,意味着它能被克隆。
TreeMap的基本操作 containsKey、get、put 和 remove 的时间复杂度是 log(n) 。 另外,TreeMap是非同步的。 它的iterator 方法返回的迭代器是fail-fastl的。
其结构是红黑二叉树,具有二叉树的所有特点,同时红黑树又是自平衡树,导致了TreeMap里面的数据呈有序排列。
二叉树的基本特点(要考):树中的任何节点的值都要大于他的左节点小于他的右节点。
红黑二叉树的基本规则(要考):
1.每个节点都只能是红色或者黑色
2. 根节点是黑色
3. 每个叶节点或者空节点是黑色的
4. 如果一个节点是红的,那他两个子节点必定是黑色的。
5. 从任一节点到其每一个叶子节点的所有路径都包含相同的黑色节点。
其中TreeMap的基本实现图如下所示:
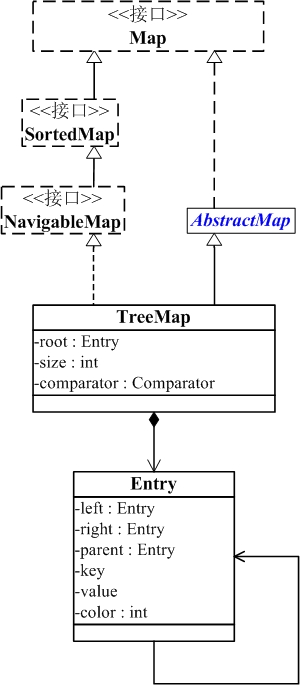
TreeMap的数据都是存放在Entity中的,同时也是树的节点。
要考部分
Entry包含了6个部分内容:key(键)、value(值)、left(左孩子)、right(右孩子)、parent(父节点)、color(颜色)
Entry节点根据key进行排序,Entry节点包含的内容为value。
HashSet是怎么去重的
HashSet底层是以散列表的形式存在的,当我们插入一个元素的时候,根据该元素的HashCode直接插入到对应的位置。
HashSet 底层是通过HashMap来实现的,通过将我们要存储的值作为key值(HashMap的key是通过HashCode去重的),存放在数组中,达到去重的目的。
那么对于HashSet,如果e已经存在(先HashCode相同定位到链表,然后equals比较定位到具体的Node),那么覆盖oldValue(value其实就是个傀儡,没啥用),Key不变;如果不存在,就添加一个新的节点(即加了一个新的Key)。
HashMap和HashTable的区别
-
相同点:HashMap和HashTable 都直接或间接的实现Map,Cloneable(可复制),Serializable(可序列化)这三个接口。
-
HashMap几乎等价HashTable,但HashMap是非线程安全的,并可以接受null的键值对。
-
HashTable线程安全,意味着多个线程可以共享一个HashTable,JDK5之后使用了ConcurrentHashMap替代了HashTable。
-
HashMap的迭代器是快速失败的,而HashTable不是。当有其他线程改变了HashMap的结构(增加或者移除),将会抛出ConcurrentModificationException, 但迭代器本身的remove()方法不会抛出该异常。
-
由于HashTable是线程安全的同时也是synchronized(同步)的,所以在单线程环境下,比HashMap慢很多。
-
想要让HashMap同步,可以使用Collection.synchronizeMap(hashMap)方法进行同步。
HashSet和HashMap的区别

HashMap扩容原理
当我们存放的HashMap到达我们的负载因子后(默认16*0.75),HashMap会和其他集合(ArrayList)类型一样, 会创建一个比原来大两倍的HashMap的bucket数组,然后重新调整Map的大小,将原来的对象放入新的数组中,这个过程叫做rehashing
另外,在调整大小的过程中,存储在链表中的元素的次序会返回来,因为移动到新的数组位置的时候,HashMap并不会将原属放在链表的尾部,而不放在头部,为了避免尾部遍历。
(重点要考)但上述情况在JDK1.8已经做出了优化,通过tail指针,既避免了死循环问题(让数据直接插入到队尾),又避免了尾部遍历。 代码如下所示:
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
Node<K,V> loHead = null, loTail = null; // JDK1.8改进了rehash算法,扩容时,容量翻倍,新扩容部分,标识为hi,原来old的部分标识为lo
Node<K,V> hiHead = null, hiTail = null; // 声明了队尾和队头指针。
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
快速失败和安全失败
fail-fast :快速失败,当在遍历一个集合时,若集合被改变则抛出CurrentModification异常。
fail-safe :安全失败,去底层集合作一个拷贝,遍历被拷贝的数组,这样就算当前数组改变了也不会抛出异常。java.util.concurrent 包下面的类都是安全失败的。
HashMap和HashTable如何进行HashCode的计算
-
HashMap计算Hash是对key的HashCode进行了二次Hash,获得更好的散列值,然后对HashTable取模。
-
HashTable计算hash的方式是直接对使用的key的HashCode对table数组的长度取模。
为什么String, Integer这样的wrapper类适合作为键?
String, Integer这样的wrapper类是final类型的,具有不可变性,而且已经重写了equals()和hashCode()方法了。其他的wrapper类也有这个特点。不可变性是必要的,因为为了要计算hashCode(),就要防止键值改变,如果键值在放入时和获取时返回不同的hashcode的话,那么就不能从HashMap中找到你想要的对象。
目前博主就遇到这一个问题,如果有小伙伴遇到其他问题,欢迎私信博主,博主QQ:375160958
JDK8中的HashMap
HashMap 在 JDK8中又加入了红黑二叉树的模型,当链表的长度大于8时,就链表就转换成了红黑二叉树的形式。
同时加入了Node这个HashMap的内部类,Hash碰撞概率跟Node(哈希桶)的大小有关。